Great question @jan, and thanks to @Voice_First for sharing how you do it!
I absolutely see that your approach “The app is in state X, now do one thing and assert that is arrives in state Y.” is in the true spirit of a unit test, and makes sense if
- you can be sure that X is a state that your voice app will naturally arrive at, and
- it has no practical value to assert that the voice app arrives in state X through a sequence of requests.
When I developed ‘Mau-Mau’, I used a similar approach, but back then with session attributes and in Postman because I didn’t know about Jovo, and the testing functionality wasn’t was mature as it is today.
For the next deep voice app that I’ll develop, I’ll also make use of manipulating the user object directly.
Recently I’ve been working more with relatively flat voice apps that have few states to go through before you get a result. For these cases, my approach is to use unit testing to assert that the entire dialog happens as planned. In this sense, it’s more of an end-to-end testing.
The way I do this while allowing for variation in the response texts is to test against the translation keys from i18n. The way I do this is by setting the locale of my unit tests to a dummy value so that i18n doesn’t resolve them, and then making sure that the response string contains the respective key(s):
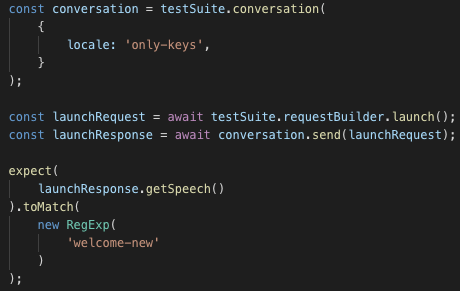
In case of a dialog with turns, I include multiple assertions in one test:
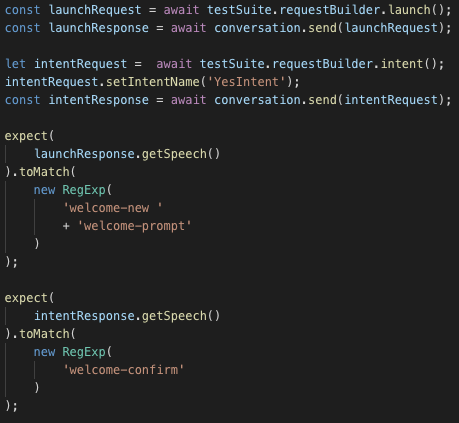
This might seem inefficient, but with the number of tests I wrote so far, it hasn’t been particularly slow. And I found it a great way of making sure that certain paths through my voice apps work as intended.
One challenge with this approach is how to assert the correct behavior in case of APL, where parts of what the app says to the user comes from the SpeakItem command.
Looking forward to hear your thoughts on this, and/or other approaches! 
